ChatGPTで会話できるAIロボットを作ってみた!
ChatGPTの登場によって, 会話ならではの砕けた表現であっても正しく意味理解し, 適切な回答の生成ができるようになってきました.
そこで今回は音声認識"Whisper"とChatGPTを組み合わせて, スタックチャンと会話できるようにしてみました. ぜひお試しを!
M5StackからChatGPTのAPIを使用できるようにしました!
C++からChatGPTのAPIを使用したい方はこちらから使い方を参照してください.

システム
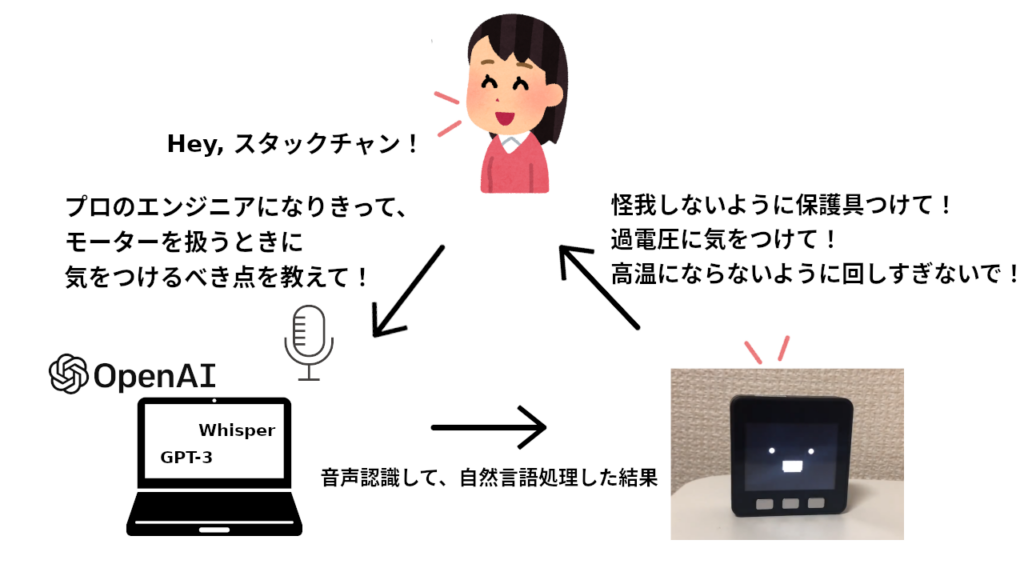
ユーザーが話しかけると, コミュニケーションロボットが返答するシステムを作成しました.
ユーザーの発言をPCのマイクが受信し, その音声をOpenAIのWhisperが文字情報に変換し, こちらもOpenAIのChatGPTがその文字情報に対する回答を作成します.
この回答をUDP通信を介してM5Stackに送信し, AquesTalkによって声に変換します.
使用しているM5Stackは下のリンクから購入できます. ここでの使用法以外にも色々な用途で使えます.
セットアップ
PC
スペック
OS:Ubuntu 20.04 LTS
GPU:GeForce RTX 2080 Ti
GPUはWhisperを動作させるために使用しました. 音声認識機能をSiriで代用する例もあるみたいです.
Whisper APIを使用する場合はGPUは不要で, CPUだけで動作させることが可能です.
AlexaLikeWhisper
今回は人間の声を取り込まないといけないのですが, それにはWhisperが最適です. Whisperの登場で市販品の音声認識と遜色ないものをフリーで使用することができます. Whisperをそのまま使用してもよいのですが,
常に重い処理を実施するより, ある程度限定された時間だけに限って音声認識をする方がスマートです.
このAlexaLikeWhisperというライブラリはWakeup Wordを検出して, Whisperで音声認識するライブラリです.
いつもはsleep状態で待機しつつ, “OK, Google", “Alexa"や"Hey, Siri"というような呼びかけ(wakeup word)に応じて音声認識します. インストールには下記記事のセットアップを参考にしてみてください.

OpenAI
OpenAI APIは人間が行うような自然言語生成を行うことができ, 例えば質問や会話の問いかけに返答するような言葉を生成することができます. 今回はWhisperで聞き取った言葉に対する返答の作成をOpenAI APIに担わせます.
pip install openai
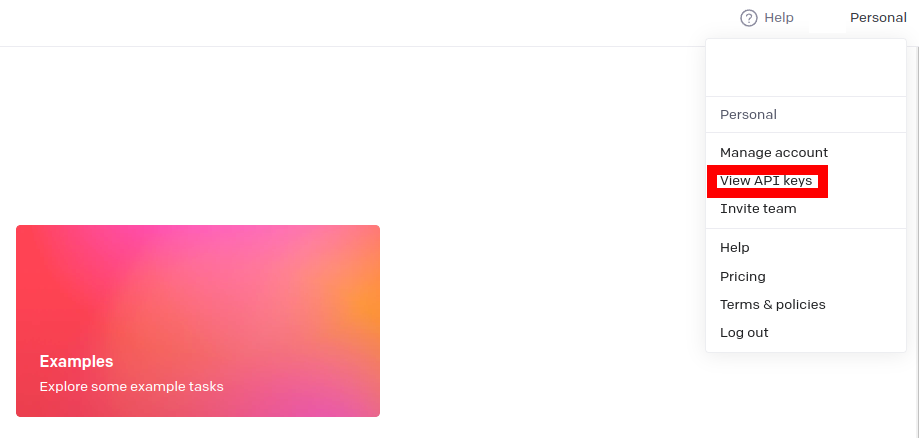
使用するために, APIKeyを取得しておきます. View API keysからAPI Keysにアクセスして, SECRET KEYを取得します.
pykakasi
OpenAIのAPIのChat機能を用いて作成した, 質問に対する返答はひらがなと漢字で構成されています.
一方で後述する"AquesTalk-ESP32″ではローマ字形式のテキストを用いて音声合成します.
そこで, PCからM5Stackへ質問に対する返答を渡すとき, 予めローマ字に変換しておきます.
pykakasiはひらがなと漢字で構成されている文章をローマ字に変換してくれるので, 今回はこのライブラリを使用します.
pip install pykakasi
M5Stack
M5Stackの開発環境として, PlatformIO環境を用いました. プロジェクトを新規作成して, espressif32のバージョンを4.0.0にします. 続いてライブラリからM5UnifiedとM5Stack-Avatarをインストールしていきます.
M5Unified
M5Stackの標準ユーティリティ機能を実装する上で, このライブラリを追加します.
M5Stack-Avatar
スタックチャンの顔を表示するライブラリ. 声に合わせて口を動かす, リップシンク機能もこのライブラリが担います.
AquesTalk-ESP32
テキストの文字情報から音声合成をするためのライブラリです. このライブラリを用いてM5Stack内蔵スピーカーを制御し, 質問に対する返答を音声にします.
下記ページの"その他->AquesTalk ESP32->Download"からESP32版のAquesTalkをダウンロードし,
zipフォルダ内のlibaquestalk.aをlibフォルダに配置します.
プログラム
PC
PCでは音声の文字変換, その文字情報を元にユーザーへの返答の作成とM5Stack側のAquesTalkで音声変換のために, その返答のローマ字変換を実施しています.
音声変換
まずは音声の文字変換です.
“alexa_like_whisper"というライブラリでWakeUpWordを検出後, 設定した時間分の音声を文字に変換し, 戻り値として返しています.
具体的には"Hey, スタックチャン"と呼びかけてから数秒間, マイクが録音して音声情報(wavファイル)を取得し, Whisperでその音声を文字へ変換し, resultへその結果を格納しています. その時以外は以下の文字列がresultに格納されます.
- 呼びかけ待ちのときは"Sleep"
- 呼びかけられた瞬間は"Wake"
- 録音中は"On recording…"
Whisper APIを使用する場合, export OPENAI_API_KEY=’YOUR_API_KEY’と環境変数を設定し, WHISPER_APIにTrueを代入してください.
import alexa_like_whisper
if __name__ == "__main__":
# Modelsizes on whisper
MODELSIZES = ['tiny', 'base', 'small', 'medium', 'large']
# AccessKey obtained from Picovoice Console (https://console.picovoice.ai/)
ACCESS_KEY = "ACCESS_KEY"
KEYWORD_PATH = ['model/Hey-stack-chan_en_linux_v2_1_0.ppn']
# Recording Time(s)
RECORDING_TIME = 5
# if using API, set True
WHISPER_API = True
alexa_like = alexa_like_whisper.AlexaLikeWhisper(ACCESS_KEY, KEYWORD_PATH, MODELSIZES[3], RECORDING_TIME, WHISPER_API)
while True:
result = alexa_like.run()
GPT-3による返答作成
次は聞き取って文字起こししたユーザーの会話に対する回答をChatGPTで作成します.
openai.ChatCompletion.createのpromptに会話を入れると, その結果が返ってきます.
例えば"プロのエンジニアになりきって、モーターを扱うときに気をつけるべき点を教えて"とクエリすると,
“怪我しないように保護具をつけて"と返答が返ってきます.
import openai
openai.api_key = "API-Key"
def ChatGPTQuery(query):
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたは役に立つアシスタントです。"},
{"role": "user", "content": query}
]
)
return response["choices"][0]["message"]["content"]
if __name__ == "__main__":
query = "プロのエンジニアになりきって、モーターを扱うときに気をつけるべき点を教えて"
result = openAIQuery(query)
ローマ字変換
M5Stackのaquestalkでしゃべらせるには, 最終的にはローマ字表記である必要があります.
そこでpykakasiというライブラリでChatGPTの作成した返答をローマ字へ変換します.
例えば"怪我しないように保護具をつけて"という文字であれば,
“kegasinaiyounihogoguwotukete"とローマ字変換されます.
このローマ字変換された段階で, UDP通信し, M5Stackへ送信します.
import pykakasi
kks = pykakasi.kakasi()
result = "怪我しないように保護具をつけて"
converted_data = kks.convert(result)
message = ''
for i, res in enumerate(converted_data):
message += converted_data[i]['passport']
M5Stack
M5Stackではローマ字化された返答をAquesTalkで喋らせていきます.
TTS.playに喋らせたいローマ字を与えてやると, M5Stackがしゃべってくれます.
#include <AquesTalkTTS.h>
String s;
const char *str;
s = "kegasinaiyounikiwotukete"
str = s.c_str();
TTS.play(str, 80);
デモ
デモ用コードを用意しました.
PC側
デモ用コードを取得します.
git clone https://github.com/tech-life-hacking/TalkingStackchan.git
example.py内のACCESS_KEY, KEYWORD_PATH, M5_IPADDRESS, openai.api_keyを編集して, example.pyを実行させます.
cd TalkingStackchan
python example.py
M5Stack
M5StackのWiFiのssidとpasswordを設定し, ビルド後, M5Stackに書き込みます.
#include <AquesTalkTTS.h>
#include <M5Unified.h>
#include <Avatar.h>
#include <tasks/LipSync.h>
#include <WiFi.h>
#include <WiFiUDP.h>
void play(const char *);
void face(String);
String UDPrecv(void);
using namespace m5avatar;
Avatar avatar;
const Expression expressions[] = {
Expression::Angry,
Expression::Sleepy,
Expression::Happy,
Expression::Sad,
Expression::Doubt,
Expression::Neutral
};
const char *AQUESTALK_KEY = "XXXX-XXXX-XXXX-XXXX";
const char *ssid = ""; // WiFi ssid
const char *password = ""; // WiFi Password
String s;
const int port = 50100; // port
WiFiUDP udp;
const char *str;
void setup() {
int iret;
M5.begin();
M5.Speaker.begin();
// Wi-Fiモジュールの開始
WiFi.disconnect(true, true); // WiFi OFF, eraseAP=true
delay(500);
WiFi.mode(WIFI_STA);
WiFi.begin(ssid, password);
udp.begin(port);
// For Kanji-to-speech mode (requires dictionary file saved on microSD)
iret = TTS.create(AQUESTALK_KEY);
avatar.init();
avatar.addTask(lipSync, "lipSync");
}
void loop() {
M5.update();
s = UDPrecv();
if (s.equals("Sleep") || s.equals("On recording...") || s.equals("Wake"))
{
if (TTS.isPlay())
{
avatar.setExpression(expressions[5]);
}
else
{
face(s);
}
}
else
{
str = s.c_str();
play(str);
}
}
void play(const char *str) {
M5.Speaker.setVolume(3);
TTS.play(str, 80);
}
void face(String state) {
if (state.equals("Sleep"))
{
avatar.setExpression(expressions[1]);
}
else if (state.equals("On recording..."))
{
avatar.setExpression(expressions[5]);
}
else if (state.equals("Wake"))
{
avatar.setExpression(expressions[5]);
}
}
String UDPrecv(void) {
char packetBuffer[1024];
int packetSize = udp.parsePacket();
if (packetSize)
{
int len = udp.read(packetBuffer, packetSize);
if (len > 0)
{
packetBuffer[len] = '\0'; // end
}
s = packetBuffer;
}
return s;
}
うまくPCとM5StackがUDP通信できると下のTwitter動画のようにロボットとコミュニケーションをとれるようになります.
遭遇したエラー
音声が起動後1回目以降鳴らなくなる
espressif32のバージョン4.1.0でI2S周りの変更が入り, aquestalkの一部が機能しなくなることがあるようです. 今回はespressif32のバージョンを4.0.0以下にデグレードし, エラーを回避しました.

AquesTalkでは発音できない言葉
記号がローマ字に混ざると発話できなくなるので, そうしたものは削除する必要があります.
def remove(message):
symbols = ["(", ")", "!", ":", "・", "?", "?", "&", " "]
for symbol in symbols:
message = message.replace(symbol, "")
return message
数字の場合は<NUMK VAL="">で囲う必要が有ります.
def number_reading(self, message):
numbers = list(set(re.findall(r"\d+", self.response)))
for num in numbers:
message = message.replace(num, "<NUMK VAL=" + num + ">")
return message

おわりに
今回はChatGPTを使って, コミュニケーションできるロボットを作成しました. AIの発達でどんどん皆さんが想像するSFの世界の出来事に近づいていっている気がしますね!