OpenAIのWhisperを使ってAlexaのように音声認識してみる!
OpenAIから高精度な音声認識"Whisper"がリリースされました. このWhisperは英語だけでなく, 多言語に対応しており, そこには日本語も含まれます. 今回はこのWhisperを使って, Alexa風に音声認識できるパッケージを作成してみました!参考にしてみてください.
Whisper
OpenAIからリリースされた高精度な音声認識ライブラリです. 漢字の間違え等はありますが, 日本語であっても,体感ではほとんど完璧に文字起こししてくれます.
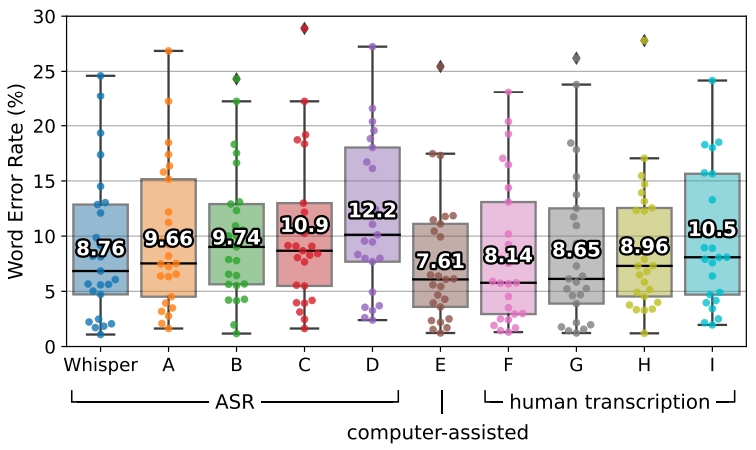
上図はある25個の録音物を音声認識し, 単語誤り率を計測した結果です.
Whisperの音声認識は無料で使用できるにも関わらず非常に優れていて, 自動音声認識(Automated Speech Recognition)の中でも市販のもの(A-D)より正確で, 人間の文字起こしサービス(F-I)と遜色なく音声認識できています.
単語誤り率(Word Error Rate)は音声認識で文字に変換した結果の内, 正解した単語数と誤った単語数の比率で, 低いほど誤りが少なく, 正しく音声認識できたことを示します.
システム定義
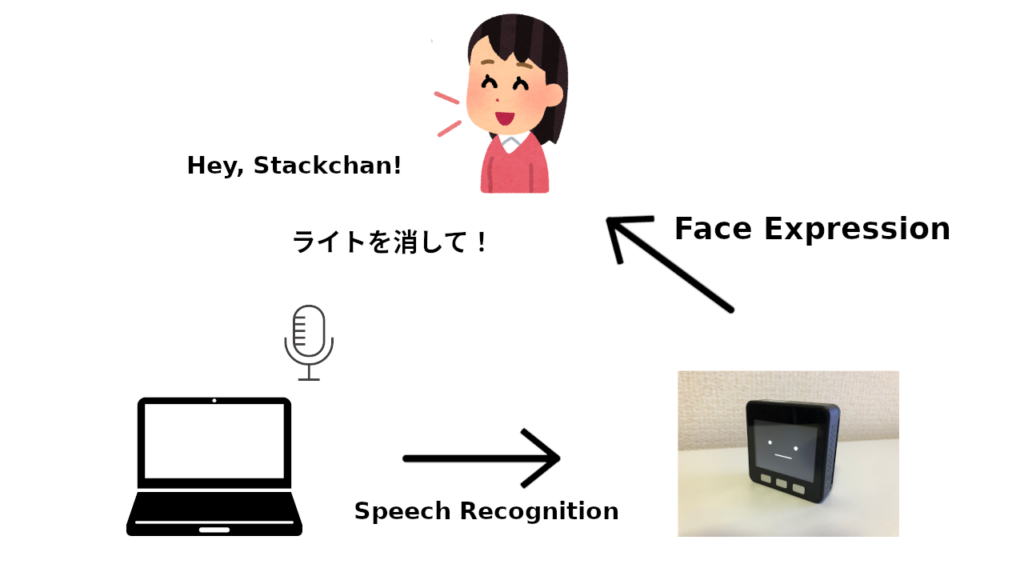
今回のシステムは音声認識ライブラリ"Whisper"を搭載したPCで, マイクを通して, ユーザーの声を受け取り, 文字に変換します.
変換された文字によって様々なタスクを実施し, その実行状態をM5Stackを通してユーザーに伝えます.
使用しているM5Stackは下のリンクから購入できます. ここでの使用法以外にも色々な用途で使えます.
使用PC
下記スペックのPCでWhisperを実行しました. Mediumサイズでも, Whisper実行時, 6GB程度GPUのメモリを占有する程, 重いモデルです. エッジデバイスだと実行は難しいと思います.
PCスペック
OS : Ubuntu 20.04
GPU : Geforce RTX2080Ti(11GB)
Whisper APIが公開され、スペックに依らずWhisperを実行できるようになりました!
セットアップ
Whisper APIを使用する場合
WhisperにもAPIが登場し, GPUの搭載されていないPCでも動作させることができるようになっています.
計算資源を提供してもらうので, APIを使用するときは有料になります.
使用する場合はOpenAIライブラリからWhisper APIを叩きます.
OpenAI
pip install openai
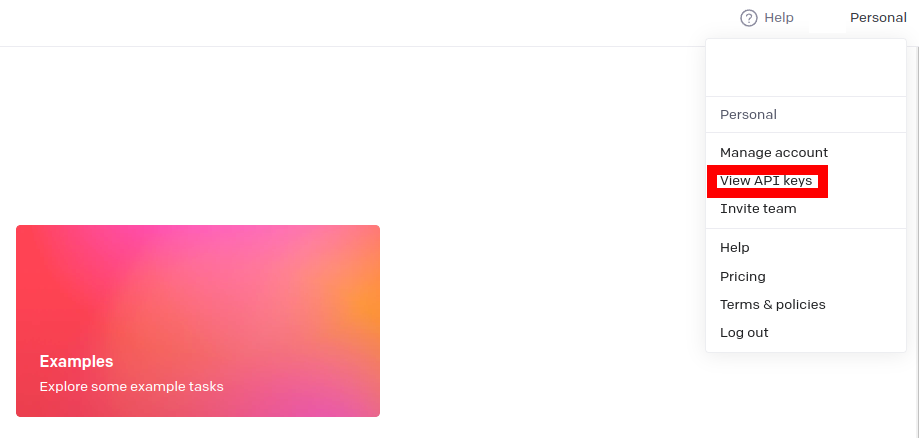
使用するために, APIKeyを取得しておきます. View API KeysからAPI Keysにアクセスして, SECRET KEYを取得します.
Whisper APIを使用しない場合
Whisper APIを使用せず, PCにWhisperをインストールする場合の手順です.
Pytorch
GPU, CUDAとcuDNNのバージョンを合わせてPytorchをインストールします.
Trasnsformers
事前学習済みモデルを簡単にダウンロードしたり, 推論できるライブラリをインストールしておきます.
Tested on Python 3.6+, Flax 0.3.2+, PyTorch 1.3.1+ and TensorFlow 2.3+.
# install transformers
pip install transformers
Whisper
今回用いる音声認識のライブラリです.
Tested on Python 3.9.9 and PyTorch 1.10.1
# install whisper
sudo apt update && sudo apt install ffmpeg
pip install git+https://github.com/openai/whisper.git
Whisper以外のライブラリ
pyaudio
音声を取得するためのライブラリをインストールします.
Tested on Python 3.10-
# install pyaudio
sudo apt-get install portaudio19-dev
pip install pyaudio
wakeup word detection
常に重い処理を実施するより, ある程度限定された時間だけに限って音声認識をする方がスマートです. “OK, Google"や"Hey, Siri"の呼びかけはまさにそれにあたり, そのwakeup wordを呼ばれるまで音声認識せず, sleep状態にしています. 今回はそのwakeup wordを検出するライブラリをインストールします.
# install pvporcupine
pip install pvporcupine
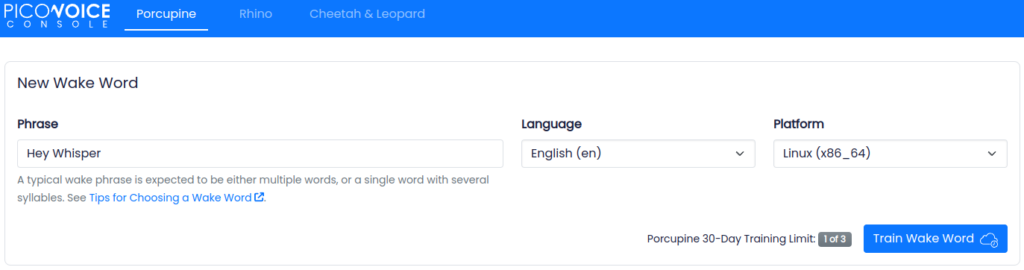
このライブラリにはAPIアクセスキーが必要なので, 下記のサイトでユーザー登録して取得しておきます.
好きなフレーズを学習して, その結果のppnファイルを後にダウンロードするAlexaLikeWhisperのmodelフォルダに保存します. そのファイルをロードすれば, Wakeup Wordとして使用できます.
Alexa Like Whisper
Wakeup Wordを検出して, Whisperで音声認識するライブラリです.
# get source of alexa like whisper
git clone https://github.com/tech-life-hacking/AlexaLikeWhisper.git
cd AlexaLikeWhisper
pip install -e .
使い方
AlexaLikeWhisperのrunメソッドを使用して, マイクから入力を受け取り, 音声認識した結果をresultに格納されます. resultに格納されるものは状態によって以下の通りに変化します.
- Wakeup word待ちのときは"Sleep"
- Wakeup wordを検出し, 録音中は"On recording…"
- 録音したものを音声認識時, その結果
Wakeup Word機能にはpvporcupineを使っているので, AlexaLikeWhisperの引数にはそのAPIキー, モデルパスを与えます. また音声認識をWhisperで行っているので, モデルサイズを指定してます. 加えてWakeup Word検出後, 音声認識する録音時間をどの程度するか決めます.
Whisper APIを使用する場合は, export OPENAI_API_KEY=’YOUR_API_KEY’と環境変数を設定し, WHISPER_APIにTrueを代入します.
後はresult結果を使って, M5Stackに表情をつけたり, 家電をコントロールをするとよいと思います.
import alexa_like_whisper
if __name__ == "__main__":
# Modelsizes on whisper
MODELSIZES = ['tiny', 'base', 'small', 'medium', 'large']
# AccessKey obtained from Picovoice Console (https://console.picovoice.ai/)
ACCESS_KEY = "YOUR_ACCESS_KEY"
KEYWORD_PATH = ['PPN_FILE_PATH']
# Recording Time(s)
RECORDING_TIME = 3
# if using API, set True
WHISPER_API = True
alexa_like = alexa_like_whisper.AlexaLikeWhisper(ACCESS_KEY, KEYWORD_PATH, MODELSIZES[3], RECORDING_TIME, WHISPER_API)
while True:
result = alexa_like.run()
print(result)

終わりに
今回は無料でも使える音声認識ライブラリ"Whisper"を紹介しました. 使ってみると, その認識精度に驚くと思います. ぜひお試しを!
また、このプロジェクトでは、Whisperを用いてAlexaのような音声認識機能を実装していますが、Whisperの精度と多言語対応を活用して、さらに多様な音声アプリケーションを開発することができます。例えば、多言語対応のチャットボットや、音声で操作できるスマートホームデバイス、音声アシスタントなど、Whisperを活用した様々なプロジェクトにチャレンジしてみてください。